Парсинг компьютерных комплектующих
Описано создание программы собирающую информацию о ценах компьютерных комплектующих и их характеристик для создания сайта агрегатора.

Введение. В современном мире обновление и поддержка работоспособности персонального компьютера имеет большое значение для многих пользователей. Постоянный технологический прогресс приводит к тому, что недавно купленное «новое железо» спустя пару лет может сильно отставать по конфигурации от системных требований современных программ и приложений. В связи с этим перед пользователем встаёт вопрос о поиске самого выгодного для себя предложении во многих магазинах электронной техники. Процесс сбора информации вручную может быть долог и утомителен, из-за чего возникает необходимость в его автоматизации.
Цель работы – разработка программы, автоматизирующей сбор информации о компьютерных комплектующих из различных интернет-магазинов для дальнейшего использования при создании сайта агрегатора.
Постановка задачи. Автоматизированный сбор данных с интернет-сайтов принято называть парсингом. Парсинг позволяет анализировать материал веб-страницы, вычленять из него необходимую информацию и преобразовать её в подходящую форму для дальнейшего использования [1]. Программа, осуществляющая такой процесс, соответственно называется – парсером.
Для написания парсера рассмотрим язык программирования Python, а в частности две библиотеки которые он предлагает для решения задач парсинга – Requests и Selenium.
Модуль Requests предоставляет возможность управления HTTP-запросами. Она проста в использовании и предоставляет программисту большой спектр функций, например, использование Cookie или задержка соединения [2]. Но тем не менее Requests не предназначен для парсинга ответа сервера, из-за чего её практически всегда используют в паре с другой библиотекой - Beautiful Soup. Модуль Beautiful Soup «помогает отформатировать и систематизировать грязные интернет-данные, исправляя плохо размеченные HTML страницы и выводя их в виде легко обрабатываемых объектов Python, представляющих собой XML-структуры» [1, c.24]. Таким образом Requests и Beautiful Soup, работая в тандеме, прекрасно подходят для решения задач парсинга.
Другая популярная библиотека, Selenium, изначально была разработана для автоматизированного тестирования работы сайтов, но её функционал оказался также удобен и для парсинга. Selenium представляет из себя драйвер браузера имитирующий действия реального пользователя, прописанные программой. Эта библиотека прекрасно подходит для парсинга сайтов с большим количеством JavaScript элементов и необходимостью обрабатывать Ajax запросы [4].
Чтобы понять какая из библиотек подходит для наших задач больше всего, сначала нужно определиться с тем какие сайты будут парситься. Используя инструмент проверки поисковых систем «pr-cy.ru», по ключевым словам - «компьютерные комплектующие», в поисковой системе «Яндекс», региона «Новосибирск», были выбраны первые 3 популярных сайта: dns-shop.ru, citilink.ru, novosibirsk.e2e4online.ru. В связи с большим количеством JavaScript элементов на этих сайтах, было принято решение использовать для работы библиотеку Selenium.
Проектирование. Объектом парсинга, как уже было обговорено являются компьютерные комплектующие. Прежде всего при покупке комплектующей пользователя интересует её цена, характеристики и модель. Так как данные полученные парсингом, планируются использоваться для создания сайта агрегатора, также необходимо спарсить ссылку на страницу товара, и его картинку для презентабельности. Все необходимые данные о товаре у большинства сайтов электроники располагается на ветрине, это значит, что нет необходимости открывать каждую страницу товара, что значительно сокращает процесс парсинга.
Так же необходимо выделить с какими именно комплектующими будет проводиться работа. Было сформировано девять категорий комплектующих необходимых для нормальной работы компьютера: процессоры (CPU), видеокарты (GPU), оперативная память (RAM), материнские платы, твердотельные накопители (SSD), жёсткие диски (HDD), системы охлаждения, блоки питания и системные блоки.
Процесс парсинга в данной работе можно разделить на 2 этапа:
Первый этап – сбор данных. На этом этапе происходит сбор информации обо всех имеющихся компьютерных комплектующих, со всех трёх определённых ранее сайтов. Для этого пишется по три отдельных программ парсеров на каждую из комплектующих, так как написать единую программу не представляется возможным, ввиду различия в характеристиках у комплектующих. Полученные парсингом результаты целесообразно записывать в виде вложенного списка для удобства дальнейшего структурирования.
Второй этап – структуризация. Поскольку полученные нами данные собираются использоваться в дальнейшем, нужно определиться с тем в каком виде они будут храниться. Лучшим вариантом представляется разделить все данные по таблицам на каждую из комплектующих. Поскольку характеристики одной и той же модели на разных сайтах одинаковы, а цены и ссылки на страницы товаров различаются, имеет смысл разбить исходную таблицу на две разные – одну с характеристиками, а другую с ценами. Для этого необходимо написать отдельную программу, которая из всего полученного массива данных сформирует по две таблицы на каждую из комплектующих. Для этого достаточно на том же Python’е написать пару вложенных циклов, которые сформируют два нужных списка, и с помощью библиотеки csv, записать их в csv файлы в виде таблиц.
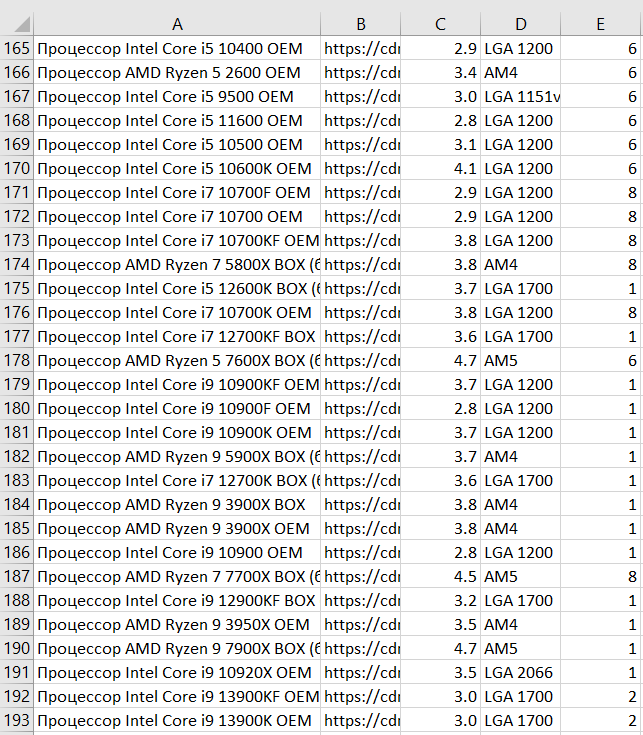
Рисунок 1. Таблица с характеристиками
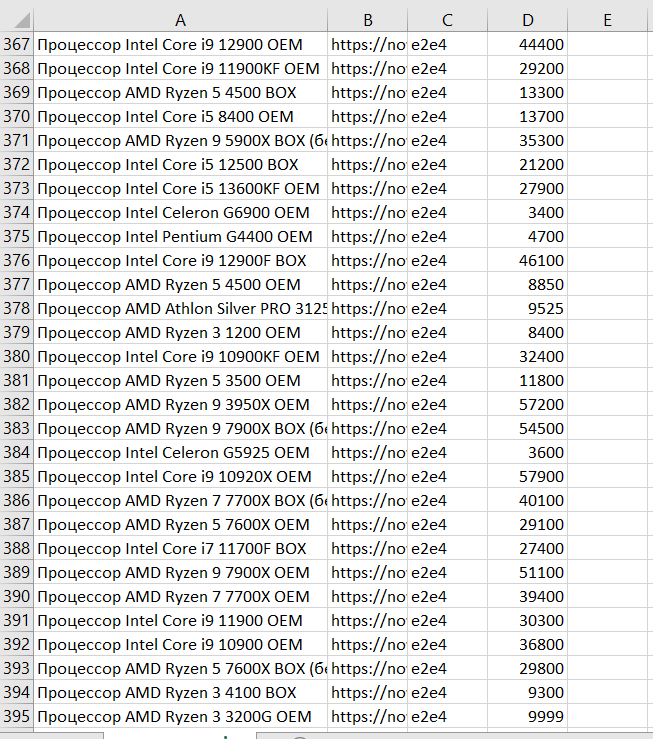
Рисунок 2. Таблица с ценами
Заключение. В результате работы программы были получены по две таблицы на каждую из девяти комплектующих, содержащих необходимую информацию для наполнения сайта агрегатора. Для примера представляется таблица процессоров с характеристиками моделей (рис.1) и таблица с ценами (рис.2).
- Что такое парсер и как он работает [Электронный ресурс]. – Режим доступа: https://timeweb.com/ru/community/articles/chto-takoe-parser (дата обращения: 7.04.2023).
- Библиотека Requests: эффективные и простые HTTP-запросы в Python [Электронный ресурс]. – Режим доступа: https://smartiqa.ru/blog/python-requests (дата обращения: 8.04.2023)
- Митчелл Р. Скрапинг веб-сайтов с помощю Python [Текст] / пер. с англ. А. В. Груздев. – М.: ДМК Пресс, 2016. – 280 с.: ил. ISBN 978-5-97060-223-2
- Чирков, А. Н. Сравнительное исследование библиотеки beautifulsoup4 и selenium для парсинга веб-страниц при помощи python / А. Н. Чирков // Научно-технические инновации и веб-технологии. – 2022. – № 1. – С. 74-78. – EDN HHTJWM.
Научные высказывания #99