Сетевая стилометрия русскоязычных интернет-текстов
Разработана единая сетевая методология для установления признаков русскоязычных интернет-текстов. Особое внимание уделено автоматизированной идентификации тематики текстовой информации Проанализированы модели, подготовлены алгоритмы и реализующие их программные инструменты. Собран корпус текстов, включающий примеры с форумов, блогов, новостных сайтов и социальных сетей. Приведены примеры Python-кодов инструментария. Продемонстрированы возможности сетевого подхода в выявлении классифицирующих признаков текстов.

Введение. В эпоху глобальной цифровизации и стремительного развития информационных технологий социальные сети стали неотъемлемой частью жизни современного человека. Социальные медиа предоставляют уникальную возможность для общения, обмена информацией и выражения мнений, но вместе с тем они представляют собой сложную и многослойную экосистему, в которой скрываются потенциальные угрозы [1]. Анонимность и легкость создания фальшивых аккаунтов делают социальные сети благоприятной средой для распространения дезинформации, мошенничества и других видов онлайн-преступности. В условиях растущей обеспокоенности по поводу безопасности и надежности информации, распространяемой в интернете, возникает необходимость в разработке и применении новых методов для анализа и мониторинга контента в социальных медиа.
Одним из перспективных подходов к решению данной проблемы является сетевой анализ, который можно использовать для установление тематики, функциональной стилистики, жанра и авторства русскоязычных текстов. Этот метод позволяет выявлять скрытые связи между различными текстовыми объектами и их авторами, что открывает новые горизонты для анализа и предотвращения угроз в интернет-пространстве. Сетевой анализ, сочетающий в себе элементы лингвистики, математической статистики и компьютерных наук, предоставляет мощные инструменты для изучения и классификации текстов, а также для определения их происхождения.
Близкие исследования. Было проведено множество исследований связанных со стилометрией, но не так много исследований было посвящено русскоязычным текстам. В качестве хорошего примера исследования в данной области можно привести работу авторов Зарубина К.А. и Труфанова А.И. “ Чувствительность сетевых метрик в стилометрии русскоязычных литературных произведений”. В данной статье предлагается развитие подхода к анализу русских литературных текстов на основе использования комплексных сетей [2]. В целом авторы ставят целью определить, насколько различные сетевые метрики эффективны для различения авторов и жанров. В исследовании применяются методы сетевого анализа, включая расчёт метрик центральности, кластеризации и плотности сети, на выборке литературных произведений разных авторов и жанров.
Результаты показывают, что определённые метрики чувствительны к различиям в стиле, что позволяет использовать их для классификации текстов и определения авторства. Исследование подтверждает практическую применимость сетевых метрик в стилометрии, подчёркивая их потенциал для автоматизированного анализа литературных произведений. Разумеется, проводились схожие исследования, к примеру, можно привести исследования Яна Рыбицкого “Братья Гримм: Стилометрический сетевой анализ” [3] или Диего Р. Амансио “Комплексный сетевой анализ языковой сложности” [4].
Модель. Для создания модели, предназначенной для идентификации тематики, функциональной стилистики, жанра и авторства интернет-текстов был определен начальный этап, включающий анализ задачи и определение целевых стилей текста. На следующем этапе во время исследования данной работы было принято решение использовать несколько моделей текстовых корпусов для более всестороннего и точного анализа. Основная причина этого выбора заключается в стремлении исследовать влияние различных этапов предобработки текста на эффективность сетевого анализа и определить наиболее информативную модель для достижения поставленных целей. Среди этих моделей можно выделить следующие.
Первая, модель с полной предобработкой текста (Model with Complete Text Preprocessing). Данная модель, включает в себя корпус текстов, который был тщательно очищен от стоп-слов, местоимений и знаков препинания, а также подвергнут лемматизации. Такая глубокая предобработка направлена на устранение всех элементов, которые могут создавать шум и искажать результаты анализа, обеспечивая максимально чистые и однородные данные для построения сетевых метрик.
Вторая модель с частичной предобработкой текста (Model with Partial Text Preprocessing) была создана на основе предыдущей модели, однако местоимения и знаки препинания были сохранены. Этот подход позволяет сохранить определённую структуру текста и проверить, в какой мере наличие местоимений и пунктуации влияет на сетевые характеристики текста и их способность различать авторские стили.
Помимо двух вышеуказанных моделей, для проверки информативности было решено использовать 2 дополнительные модели "Мешок слов" (Bag of Words) [6] и "Сети смежных слов" (Word-adjacency Networks) [7].
В процессе обработки текста алгоритмом, основанным на модели "Мешок слов" (Bag of Words), текст проходит предварительную лемматизацию и удаление стоп-слов. Затем текст подвергается токенизации, в ходе которой каждому уникальному слову присваивается свой уникальный идентификатор. Далее начальный текст проходит алгоритм перебора, состоящий из 2х этапов:
- Текст обрабатывается, используя “Порог”
- Текст обрабатывается, используя модель смежных слов
В процессе обработки текста алгоритмом, основанным на модели "Сети смежных слов" (Word-adjacency Networks), также проходит предварительную лемматизацию и удаление стоп-слов. Далее текст подвергается простой токенизации, в ходе которой каждому слову присваивается свой уникальный идентификатор, что избавляет наш алгоритм от создания лишнего списка с идентификаторами. Затем начальный текст также проходит алгоритм перебора, состоящий из перечисленных выше 2х этапов.
Данные алгоритмы в последствии создает 2 списка включающих в себя связи вершин являющимися по совместительству смежными словами. В отличии от 1 модели, где связи составляются, используя идентификаторы уникальных слов из отдельного списка, тут каждое слово имеет свой идентификатор.
Как было упомянуто ранее, в рамках разработки алгоритма было принято решение использовать понятие “порог” в качестве основного принципа формировании связей комплексной сети, описывающей текст. В данном контексте порогом называется максимальное значение, определяющее диапазон слов подлежащих анализу связанности с текущим словом. Этот диапазон начинается с идентификатора слова, обрабатываемого в цикле, и заканчивается указанным пороговым значением.
После проведения множества тестов было принято решение, что в качестве основной модели для исследования лучше будет использовать «Сеть смежных слов», т.к. она является более информативной моделью.
Данные. Для анализа было собрано множество текстов различных жанров и стилей, что позволило создать разнообразный и репрезентативный корпус. Каждый текст прошел несколько этапов подготовки, чтобы обеспечить его пригодность для дальнейшего исследования.
- Сбор текстов. Тексты были собраны из различных источников, включая литературу, научные публикации, новостные сайты и технические документы. Для включения в корпус текстов использовались как современные материалы, так и тексты прошлых лет, что позволило охватить широкий спектр тем и стилей.
- Очистка данных. На этом этапе тексты были очищены от посторонних символов и лишних элементов, таких как HTML-теги, рекламные вставки и прочие ненужные компоненты. Очистка данных позволила обеспечить чистоту и однородность текстов для дальнейшего анализа.
- Стандартизация формата. Все тексты были приведены к единому формату, включающему стандартизированные заголовки, абзацы и другие элементы структуры. Это упростило их обработку и анализ, обеспечивая единообразие представления данных. В качестве стандарта для исследования использовались: Шрифт размером - 12пт., Объем текста - 1 страница стандартного A4 формата.
- Анонимизация. В случае необходимости тексты были анонимизированы, чтобы удалить личную или конфиденциальную информацию. Это особенно важно при работе с юридическими и медицинскими текстами, где защита конфиденциальности является приоритетом.
Инструменты. Первым и самым главным инструментом для создания всех алгоритмов был выбран язык программирования Python. Данный язык был выбран потому-то его разработчик, Гвидо ван Россум, вложил в основу языка простоту и читабельность кода, что позволяет использовать Python для быстрой и эффективной разработки [8].
В качестве инструмента для расчета всех необходимых для исследования метрик было взято программное обеспечение Gephi. Gephi — это больше, чем просто инструмент визуализации; это комплексная платформа для сетевого анализа, позволяющая пользователям исследовать тонкости сложных систем, от социальных сетей до организационных структур и за их пределами [9].
Ну а для работы с рассчитанными метриками было решено взять Microsoft Excel, лучший инструмент для работы со всевозможными числовыми данными и таблицами.
Основные результаты. Все необходимые для изучения метрики рассчитывались по формулам, приведенным ниже:
- Средняя степень вершины (Average Degree), показатель среднего количества связей на одну вершину:
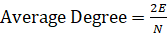 (2)
(2)
Где E — количество ребер в графе;
N — количество узлов в графе.
- Средний коэффициент кластеризации (Avg. Clustering Coefficient): измеряет степень кластеризации вершин. (добавить формулы);
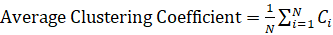 (3)
(3)
Где Ci — коэффициент кластеризации узла I:
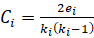 (4)
(4)
Где ei — количество ребер между соседями узла i;
ki — степень узла i.
- Средняя длина пути (Avg. Path Length), показывает среднюю длину кратчайших путей между всеми парами вершин:
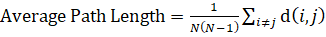 (5)
(5)
Где d (i,j) — длина кратчайшего пути между узлами i и j
Далее все рассчитанные метрики заносились в таблицы (Таблица 1)
Таблица 1
Пример рассчитанных метрик для текстов различной тематики
|
Type |
История |
||
|
Model |
30 all_7 |
30 all_8 |
30 all_9 |
|
Average Degree |
1,399 |
1,234 |
1,466 |
|
Network Diameterer |
70 |
73 |
67 |
|
Graph Density |
0,002 |
0,002 |
0,002 |
|
Modularity |
0,854 |
0,862 |
0,845 |
|
Avg.clustering coefficient |
0,029 |
0,012 |
0,039 |
|
Avg.path length |
24,151 |
28,915 |
23,665 |
На рис. 1 представлена сеть, визуализированная графом, построенным в программе Gephi. Данная сеть сгенерирована основываясь на данных, записанных в .csv файлы, автоматически сгенерированными благодаря написанному алгоритму. Выбранный алгоритм укладки "Fruchterman-Reingold", параметр гравитации на 3 единицы, разным цветом и размером показаны вершины, которые являются словами или любыми другими значениями, что чаще всего упоминаются в тексте.
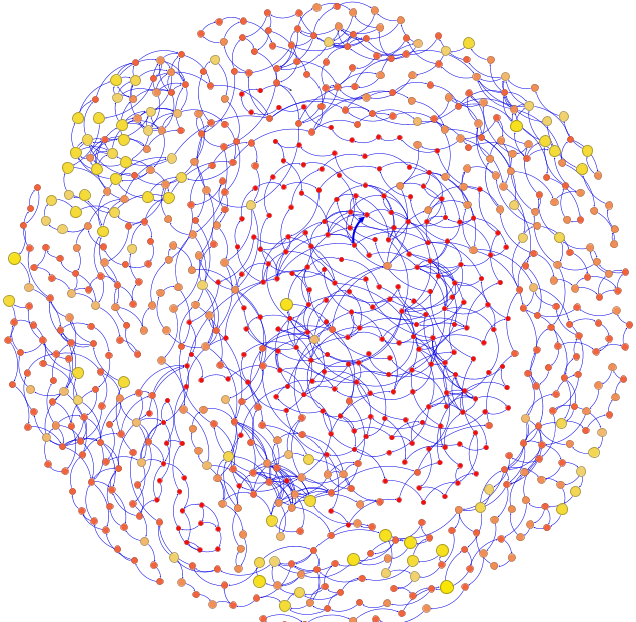
Рисунок 1. Сетевой отпечаток текста, относящегося к тематике “История”
На рис. 2 видно, как используя рассчитанные метрики создается трехмерный график, на котором показано к какой тематике склонен проверяемый текст.
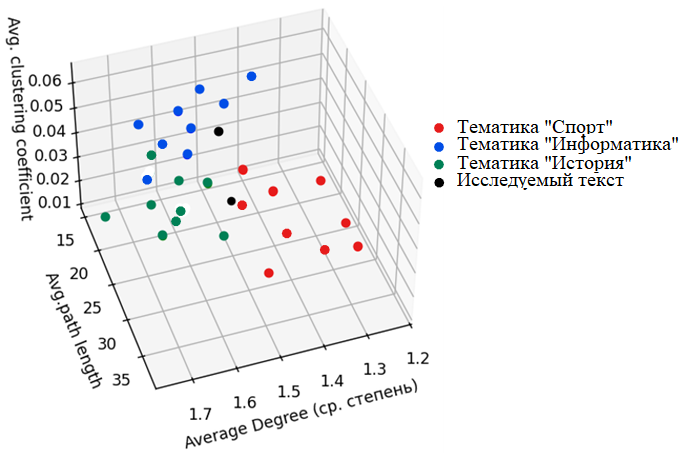
Рисунок 2. Трехмерный график, показывающий принадлежность исследуемого текста к определенным тематикам
Одной из главных особенностей данной работы, является возможность автоматической идентификации тематики, функциональной стилистики, жанра и авторства текстовой информации, благодаря написанному алгоритму на высокоуровневом языке программирования Python.
Обсуждение. Во время исследования было проанализировано множество различных текстов используя метод сетевого анализа. Результаты показывают разнообразие структурных характеристик текстов. Высокая модульность указывает на четкое разделение на сообщества, а низкий коэффициент кластеризации — на менее выраженную локальную связанность.
Работа уникальна автоматизированной идентификацией тематики, функциональной стилистики, жанра и авторства, в отличие от исследований, направленных на определение только авторства. Применение сетевого анализа важно для лингвистики, ИТ и других областей.
Дальнейшие исследования могут расширить метод на различные текстовые корпуса и включить новые алгоритмы машинного обучения для улучшения анализа.
Заключение. В данном исследовании был реализован метод сетевого анализа для идентификации тематики, функциональной стилистики, жанра и авторства текста, включающий разработку сетевой модели текста, автоматизированную подготовку данных с реализацией Python- кода, построение графов, визуализацию и анализ их структур. В качестве основного инструмента использовали — Gephi, для отображения графов и расчета метрик, что позволило выявить ключевые связи и закономерности в текстах.
Исследование показало, что сетевой анализ — мощный инструмент для изучения структуры текстов, чувствительный для выявления особенностей текстового материала. Результаты продемонстрировали значительные различия в структурных характеристиках текстов, подтверждая потенциал метода для дальнейшего его применения в решении задач стилометрии.
- Иламанов, Б. Б. Анализ и моделирование социальных сетей / Б. Б. Иламанов, Ч. Г. Мурриков. — Текст : непосредственный // Молодой ученый. — 2023. — № 48 (495). — С. 15-16. — URL: https://moluch.ru/archive/495/108277/ (дата обращения: 26.06.2024).
- Зарубин К.А., Труфанов А.И. (2023) "Комплексные Сети В Русской Классической Литературе: Атрибуция Текста И Сетевая Модель". Журнал "Обществознание И Социальная Психология", 10-5 (58), 12-18. Eissn: 2949-2637. Doi: 10.1102/J.Osps.2023.105.516.
- Rotari, G., Jander, M., & Rybicki, J. (2020). The Grimm Brothers: A stylometric network analysis. Digital Scholarship in the Humanities, 2, 1-15.
- Diego R. Amancio, Sandra M. Aluisio, Osvaldo N. Oliveira jr., and Luciano da F. Costa. "Complex networks analysis of language complexity." Published 11 December 2012. Copyright © EPLA, 2012. Europhysics Letters, Volume 100, Number 5. Citation: Diego R. Amancio et al 2012 EPL 100 58002. DOI: 10.1209/0295-5075/100/58002.
- Анализ данных с использованием Python: [сайт]. – URL: https://habr.com/ru/articles/353050/. (дата обращения: 26.06.2024)
- Mogotsi, I.C. Christopher D. Manning, Prabhakar Raghavan, and Hinrich Schütze: Introduction to information retrieval. Inf Retrieval 13, 192–195 (2010). https://doi.org/10.1007/s10791-009-9115-y (дата обращения: 26.06.2024)
- Stanisz, T., Kwapien, J., & Drozdz, S. (August 2018). Linguistic data mining with complex networks: a stylometric-oriented approach. Institute of Nuclear Physics and Cracow University.
- Основы языка программирования Python: [сайт]. – URL: https://www.nic.ru/help/osnovy-yazyka-programmirovaniya-python_11662.html (дата обращения: 26.06.2024)
- Gephi: a deep dive into Network Analysis and Visualization: [сайт]. – URL: https://digitaldatastories.it/2024/03/05/gephi-a-deep-dive-into-network-analysis-and-visualization (дата обращения: 26.06.2024)
Научные высказывания #99