Генерация естественно-языковых предложений с помощью нейронных сетей
Приведены основные определения естественного языка. Проанализирована обработка текстов. Рассмотрена работа рекуррентной нейронной сети. Рассмотрено применение рекуррентной сети для генерации предложения на естественном языке.

Введение. Обработка естественного языка – это методы, используемые для того, чтобы компьютер мог понимать естественный человеческий язык. Обработка естественного языка необходима для классификации текстовых документов или создания чат-ботов.
Приложения, которые используют обработку естественного языка, становятся частью нашей жизни. Они просматривают огромные объемы информации, предлагают новые механизмы взаимодействия человека с компьютерами. Приложения, которые анализируют речь и текст, взаимодействуют с человеком. Человек обеспечивает обратную связь. Эта связь оказывает влияние на приложение и на результаты анализа.
Приложения, основанные на использовании естественного языка, начинают распространяться и со временем будут все больше брать на себя задач.
1. Обработка написанных на естественном языке текстов (NLP). Все методы NLP начинаются с набора текстовых данных - корпуса. Корпус состоит из неформатированного текста и соответствующих тексту метаданных. Неформатированный текст состоит из символов, но обычно их группируют в непрерывные единицы данных - токены. В терминологии машинного обучения текст вместе с метаданными называется экземпляром или точкой данных. Корпус - набор примеров - называется набором данных. Процесс разбиения текста на токены называется токенизацией. Уникальные токены из корпуса называются типами. Множество всех типов в корпусе называется его словарем или лексиконом. Слова делятся на значимые и стоп-слова. Стоп-слова служат в основном грамматическим целям.
Леммы – корневые формы слова. Например, слово дом. Склоняя его можно получить множество различных слов – дома, домой, домом, о доме. И для всех этих слов, слово дом является леммой. Лемматизация – свертывания токенов до соответствующих лемм ради понижения размерности векторного представления.
Категоризация – одно из самых первых приложения NLP. Распространенный пример категоризации слов – маркирование частей речи. Довольно часто нужно маркировать отрезок текста. Например, необходимо выделить в нем именные и глагольные группы. Это называется поверхностным синтаксическим разбором. Задача такого разбора – извлечение более высокоуровневых единиц, состоящих из существительных, глаголов, прилагательных и т.д. Еще один удобный тип отрезков текста – поименованная сущность – символьное значение, упоминающее понятие реального мира, например человека, местоположение, организацию и т.д.
При поверхностном синтаксическом разборе в тексте распознаются фразовые единицы. При простом синтаксическом разборе в тексе распознаются взаимосвязи между этими единицами. Деревья синтаксического разбора демонстрируют связи различных грамматических единиц. Дерево синтаксического разбора иллюстрирует разбор на составляющие. Еще один способ демонстрации взаимосвязей – применение синтаксического разбора зависимостей.
Также у слов есть значение, и зачастую не одно. Различные значения слова называются его смыслами. Смыслы слов можно выяснить из лексической базы данных или из контекста.
2. Рекуррентные нейронные сети. В простейшей рекуррентной нейронной сети ключевую роль играет наличие петли, которая изменяет скрытое состояние нейронной сети после появления на входе каждого слова последовательности.
Чтобы работать с последовательностями конечной длины, нужно развернуть цикл в последовательность временных слоев, соответствующих различным временным меткам. Это уже представление сети прямого распространения. В сети имеются отдельные узлы для скрытых состояний в каждый момент времени, и петля развертывается в сеть прямого распространения.
Матрицы весов разделяются различными временными слоями, гарантируя тем самым, что для каждой метки времени используется одна и та же функция.
Обычно в сети для каждой временной метки имеется свой вход, выход и скрытый элемент. Но бывает и такое, что в любой момент времени входной или выходной элемент может отсутствовать. Выбор отсутствующих входов и выходов определяется спецификой конкретного приложения. В зависимости от конкретики приложения может отсутствовать любое подмножество входов и выходов.
Архитектура сетей, рассмотренная выше, приспособлена для языкового моделирования. Целью языкового моделирования является предсказание следующего слова, если известна последовательность предыдущих слов. При заданной последовательности слов их прямые коды одновременно подаются на вход нейронной сети. Этот быстротекущий процесс эквивалентен подаче отдельных слов на входы в момент времени, соответствующие временным меткам. Временные метки соответствуют позициям в последовательности, и их нумерация начинается с 0 или 1 и увеличивается на 1 при переходе вперед на один элемент последовательности. В условиях языкового моделирования выходом является вектор вероятностей, предсказанных для следующего слова последовательности.
В общем случае обозначим входной вектор в момент времени t как 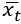 , скрытое состояние в момент времени t – как
, скрытое состояние в момент времени t – как 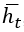 , а выходной вектор в момент времени t – как
, а выходной вектор в момент времени t – как 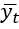 . В случае словаря размером d как
. В случае словаря размером d как 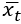 , так и
, так и 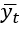 являются d-мерными векторами. Скрытый вектор
являются d-мерными векторами. Скрытый вектор 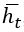 – p-мерный, где p регулирует сложность вложенного представления. Если предположить, что:
– p-мерный, где p регулирует сложность вложенного представления. Если предположить, что:
- все названные векторы являются вектор-столбцами;
- выход не генерируется элементами для каждой отметки времени, а лишь запускается на последней отметке времени в конце последовательности;
- входные и выходные элементы имеются для всех отметок времени,
то тогда скрытое состояние в момент времени t задается функцией входного вектора в момент времени t и скрытого вектора в момент времени (t-1):
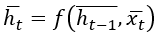 (1)
(1)
Эта функция определяется с помощью матриц весов и функций активации, причем для каждой временной отметки используются одни и те же веса. Для обучения выходных вероятностей на основе скрытых состояний применяется отдельная функция 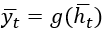 .
.
Конкретизируем функции f и g. Определим матрицу весов «вход-скрытый» 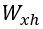 размера p×d, матрицу весов «скрытый-скрытый»
размера p×d, матрицу весов «скрытый-скрытый» 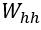 размера p×p и матрицу весов «скрытый-выход»
размера p×p и матрицу весов «скрытый-выход» 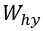 размера d×p. Тогда:
размера d×p. Тогда:
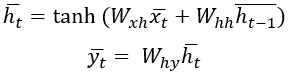
Ввиду рекурсивной природы уравнения (1) рекуррентная сеть способна вычислять функцию входов переменной длины. Рекурсию уравнения (1) можно разложить, чтобы определить функцию для 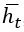 в терминах t входов. Например, начиная с вектора
в терминах t входов. Например, начиная с вектора  , в качестве которого обычно выбирают некий постоянный вектор (обычно нулевой), получаем
, в качестве которого обычно выбирают некий постоянный вектор (обычно нулевой), получаем  и
и 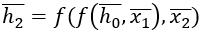 .
.  – функция, зависящая только от
– функция, зависящая только от  , а
, а  - функция зависящая и от
- функция зависящая и от 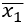 , и от
, и от 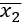 . В общем случае
. В общем случае 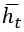 является функцией
является функцией 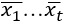 . Поскольку выход
. Поскольку выход 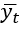 является функцией
является функцией 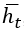 , он также наследует эти свойства. Обобщая, можно записать следующее соотношение:
, он также наследует эти свойства. Обобщая, можно записать следующее соотношение:
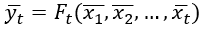 (2)
(2)
Функция Ft меняется с изменением t, хотя ее соотношение с непосредственно предшествующим состоянием всегда остается одним и тем же. Такой подход особенно полезен в случае входов переменной длины. Подобные ситуации часто встречаются во многих задачах, например при обработке текста, в котором длина предложений меняется. Например, в случае языкового моделирования функция Ft определяет вероятность следующего слова с учетом предыдущих слов предложения.
3. Пример языкового моделирования с помощью рекуррентных нейронных сетей. Иллюстрация работы рекуррентных нейронных сетей. Предложение на основе словаря, состоящего из 4 слов: {the}, {cat}, {mouse}, {chased}: The cat chased the mouse
На рисунке 1 отображено вероятностное предсказание следующего слова для каждой временной отметки от 1 до 4.
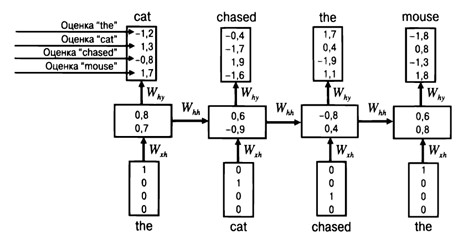
Рисунок 1. Вероятностное предсказание следующего слова
В идеале должно быть, чтобы вероятность следующего слова правильно предсказывалась на основе вероятности предыдущих слов. Длина каждого вектора 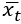 в представлении прямого кодирования равна четырем, причем только один бит равен 1, тогда как остальные равны нулю. В данном случае, основным фактором гибкости является размерность p скрытого представления, которая равна 2. В результате матрица
в представлении прямого кодирования равна четырем, причем только один бит равен 1, тогда как остальные равны нулю. В данном случае, основным фактором гибкости является размерность p скрытого представления, которая равна 2. В результате матрица 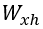 будет иметь размерность 2×4 , поэтому она транслирует входной вектор в представлении прямого кодирования на скрытый вектор
будет иметь размерность 2×4 , поэтому она транслирует входной вектор в представлении прямого кодирования на скрытый вектор 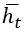 размера 2. В практическом соотношении каждый столбец
размера 2. В практическом соотношении каждый столбец 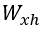 соответствует одному из четырех слов, и один из этих столбцов копируется выражением
соответствует одному из четырех слов, и один из этих столбцов копируется выражением 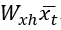 . Это выражение прибавляется к выражению
. Это выражение прибавляется к выражению 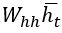 , а затем преобразуется с помощью функции гиперболического тангенса для получения окончательного выражения. Конечный вывод
, а затем преобразуется с помощью функции гиперболического тангенса для получения окончательного выражения. Конечный вывод 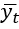 определяется выражением
определяется выражением 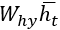 . Матрицы
. Матрицы 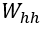 и
и 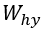 имеют размеры 2×2 и 4×2 соответственно.
имеют размеры 2×2 и 4×2 соответственно.
В данном случае выходами являются непрерывные значения, причем большие значения указывают на большую вероятность того, что данное слово будет следующим. В конечном счете, непрерывные значения образуются в вероятности, поэтому их можно рассматривать в качестве замены логарифмических вероятностей.
Как и в случае любого алгоритма обучения, нельзя надеется на то, что все значения будут предсказаны точно. Подобные ошибки наиболее вероятны на ранних итерациях алгоритма обратного распространения. Но поскольку сеть периодически тренируется на протяжении многих итераций, алгоритм со временем допускает все меньше ошибок на тренировочных данных.
4. Архитектура нейронной сети
Архитектура нейронной сети содержала два рекуррентных слоя LSTM. Первый слой содержал 64 нейрона. Далее использовался такой же слой с 32 нейронами. В рекуррентных слоях была использована функция активации гиперболический тангенс и оптимизатор Adam. На выходе содержится полносвязный слой с тремя нейронами и функцией активации softmax.
Для обучения сети предварительно была скачена база новостей из русскоязычного датсета Sentiment Analysis in Russian | Kaggle, содержащая наборы позитивных, нейтральных и негативных новостей. Показатели точности и потерь на тренировочных и валидационных данных 10 эпох обучения данной архитектуры сети представлены на рисунке 2.
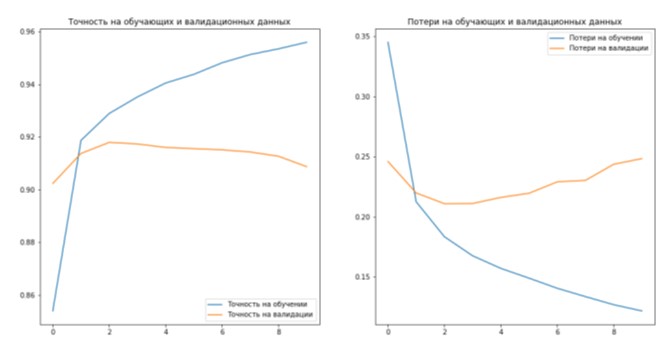
Рисунок 2. Точности и потери на тренировочных и валидационных данных
Можно заключить, что программа на основе LSTM-сети за счет своей сложной архитектуры позволяет получить достаточно высокую точность обучения даже при небольшом числе эпох.
- Чарй Аггарвал. Нейронные сети и глубокое обучение: учебный курс.: Пер. с англ. – СПб.: ООО «Диалектика», 2020. — 752с. — Парал. тит. англ.
- Бенгфорт Бенджамин, Билбро Ребекка, Охеда Тони. Прикладной анализ текстовых данных на Python. Машинное обучение и создание приложений обработки естественного языка. — СПб.: Питер, 2019. —
368с.
- Макмахан Брайан, Рао Делип. Знакомство с PyTorch: глубокое обучение при обработке естественного языка. — СПб.: Питер, 2020. — 256с.
Научные высказывания #99