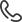Разработка Python-инструментов для R - пакета ts2net
В 2022 году Л. Феррейра опубликовал R-пакет ts2net, преобразующий временные ряды в комплексные сети и обративший на себя внимание экспертов. В данном проекте ts2net протестирован на задачах распознавания речевых записей. Собран и обработан набор аудиофайлов: подготовленный Python-инструмент с удобным интерфейсом пользователя позволяет загружать сигнал, фильтровать его, обрезать и формировать временной ряд. Использованы два языка программирования: R и Python в среде разработки Google Colaboratory, обеспечивающей бесшовный переход между ними. Представлен набор команд для обработки всех временных рядов из целевой директории с помощью функции tsnet_vg() R-пакета ts2net.

Введение. Анализ речевых сигналов является актуальной областью исследований, имеющей широкое применение в различных сферах, таких как распознавание речи, идентификация дикторов, биометрическая аутентификация, персонализация цифровых помощников и т.д. Традиционные методы анализа речи, основанные на извлечении статических признаков, таких как MFCC, LPC, и других акустических характеристик, достигли значительных успехов, однако они имеют определенные ограничения в смысле учета динамических изменений в речи и выявления тонких нюансов в голосе диктора.
В последние годы происходит активное развитие методов сетевого анализа речевых сигналов, которые позволяют представлять речь в виде сложных сетевых структур и исследовать взаимосвязи между разными частями речевого сигнала. Этот подход обещает улучшить точность и надежность систем распознавания речи и идентификации дикторов за счет учета динамических особенностей речи и выявления скрытых паттернов [4].
Пакет ts2net, разработанный Л. Феррейрой (Leonardo N. Ferreira), представляет собой мощный инструмент для преобразования временных рядов в сети, открывающий новые возможности в анализе сложных динамических систем, включая и речевые сигналы [1,2].
В данной работе представляется адаптация пакера ts2net к сетевому анализу речевых сигналов в задаче идентификации диктора. А также показана необходимость предварительной обработки аудиозаписей для подготовки временного ряда.
Близкие исследования. Традиционными методами для анализа речи являются коэффициенты мел-кепстральных частот (MFCC) и линейное предсказание коэффициентов (LPC). Эти методы позволяют эффективно извлекать особенности звукового сигнала, которые затем используются для задач классификации и распознавания дикторов. Однако с развитием сетевого анализа появились новые подходы, предлагающие более глубокое и комплексное изучение речевых данных.
Сетевой анализ речевых сигналов позволяет моделировать и анализировать взаимосвязи между различными компонентами речевого процесса с использованием концепций и инструментов сетевой теории. В отличие от традиционных методов, которые часто фокусируются на отдельных характеристиках сигнала, сетевой подход рассматривает речевые данные как сложные динамические системы, где каждый элемент (например, звуки, фонемы, слова) представляется в виде узлов сети, а связи между ними — как ребра, отражающие зависимости и взаимодействия.
Одним из первых исследований в этой области было использование метода видимости (Visibility Graph, VG) для преобразования временных рядов речевых сигналов в сети [5]. В работе Лаксы и его коллег была предложена концепция преобразования временного ряда в видимый граф, где точки данных соединяются ребрами, если они могут "видеть" друг друга на графике временного ряда. Это позволило исследовать структуру речевого сигнала с точки зрения сетевых метрик, таких как центральность узлов и кластеризация.
Ещё одно значимое исследование в этой области было проведено Ченом и его коллегами [6]. Они использовали метод горизонтальной видимости (Horizontal Visibility Graph, HVG) для анализа речевых сигналов. Их результаты показали, что HVG позволяет эффективно выделять ключевые особенности речевого сигнала, что существенно улучшает точность распознавания дикторов по сравнению с традиционными методами.
Современные исследования в области распознавания дикторов продолжают развивать и углублять применение сетевых методов [7]. Сетевые подходы предлагают новые перспективы и открывают возможности для более комплексного и точного анализа речевых сигналов, что может привести к значительным достижениям в области распознавания дикторов и схожих задач речевых технологий.
Инструменты. В ходе данного исследования активно использовались языки программирования R и Python. Разработка и отладка кода осуществлялись в бесплатной среде разработки Google Colaboratory, что обеспечивало удобный и гибкий рабочий процесс. Язык R применялся для использования основной библиотеки исследования ts2net, которая предназначена для преобразования временных рядов в сетевые структуры и написана на этом языке.
Python применялся для разработки программ, предназначенные для отображения амплитуд и спектрограмм аудиозаписей, а также преобразования аудиофайлов в .csv-файлы для последующего анализа. При реализации этой части исследования были задействованы несколько ключевых библиотек.
Библиотека librosa предназначена для работы со звуком и анализом аудиоинформации. С её помощью можно извлекать различные речевые характеристики, что важно для предварительной обработки и анализа речевых данных. Для расчетов метрик графа применялась библиотека NetworkX, которая предоставляет широкий набор инструментов для создания, манипулирования и изучения структуры сложных сетей. Библиотека matplotlib использовалась для визуализации данных. В рамках данного исследования с её помощью создавались графики амплитуды звуковых сигналов, что позволяло наглядно представлять и анализировать аудиозаписи. Библиотека pandas применялась для работы с табличными данными, что упрощало процесс конвертации аудиофайлов в формат .csv и дальнейшей обработки этих данных. Для выполнения численных операций, необходимых для обработки и анализа аудиосигналов, использовалась библиотека NumPy.
Данные. Аудиозаписи для анализа дикторов были взяты с сайта Zvukogram. Изначально файлы были представлены в формате WAV. В дальнейшем они были преобразованы в формат CSV для дальнейших преобразований во временные ряды.
Выборка состоит из аудиофайлов двух дикторов, что позволило сравнивать сетевые характеристики их речевых сигналов. Использование файла формата CSV облегчило процесс анализа сетевых характеристик с помощью библиотеки NetworkX. Эти преобразования были необходимы для дальнейшей обработки и анализа данных, обеспечивая точность и надежность полученных результатов.
Основные результаты. Параметры сигнала - временного ряда, необходимые для распознавания диктора, полагались заранее неизвестными. Для выявления чувствительных признаков предполагался необходимый их перебор и экспериментальная оценка. Общепринятый метод ускорения обработки речевого сигнала заключается в его разбиении на короткие временные окна фиксированного размера (обычно 10-30 мс), где параметры сигнала считаются постоянными. Для точности между окнами делают перекрытие, равное половине их длины.
Первоначальной задачей была подготовка Python- программы для разбиения аудиофайлов дикторов. Был создан пользовательский интерфейс, который позволяет актуализировать аудиофайлы по амплитуде, спектрограмме и фильтру низких частот. Так же была написана функция разбиении аудиофайла, для последующего сетевого анализа. Пользовательский интерфейс представлен на рисунке 1.
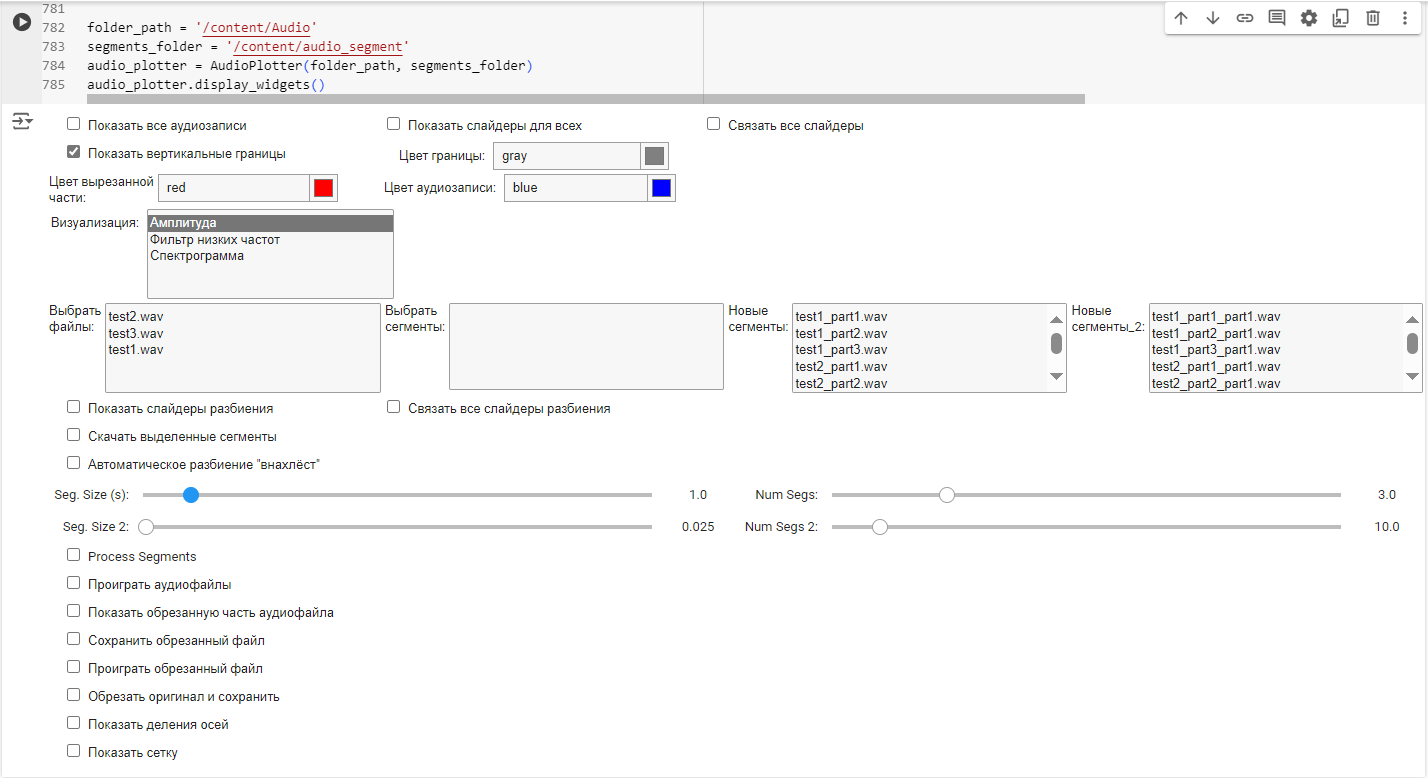
Рисунок 1. Пользовательский интерфейс
Разбиение аудиофайла происходит по методу “внахлест”, данный метод предполагается, что каждый последующий сегмент будет идентичен друг другу на 50% , т.е текущий конец сегмента будет в начале последующего (см. рисунок 2).
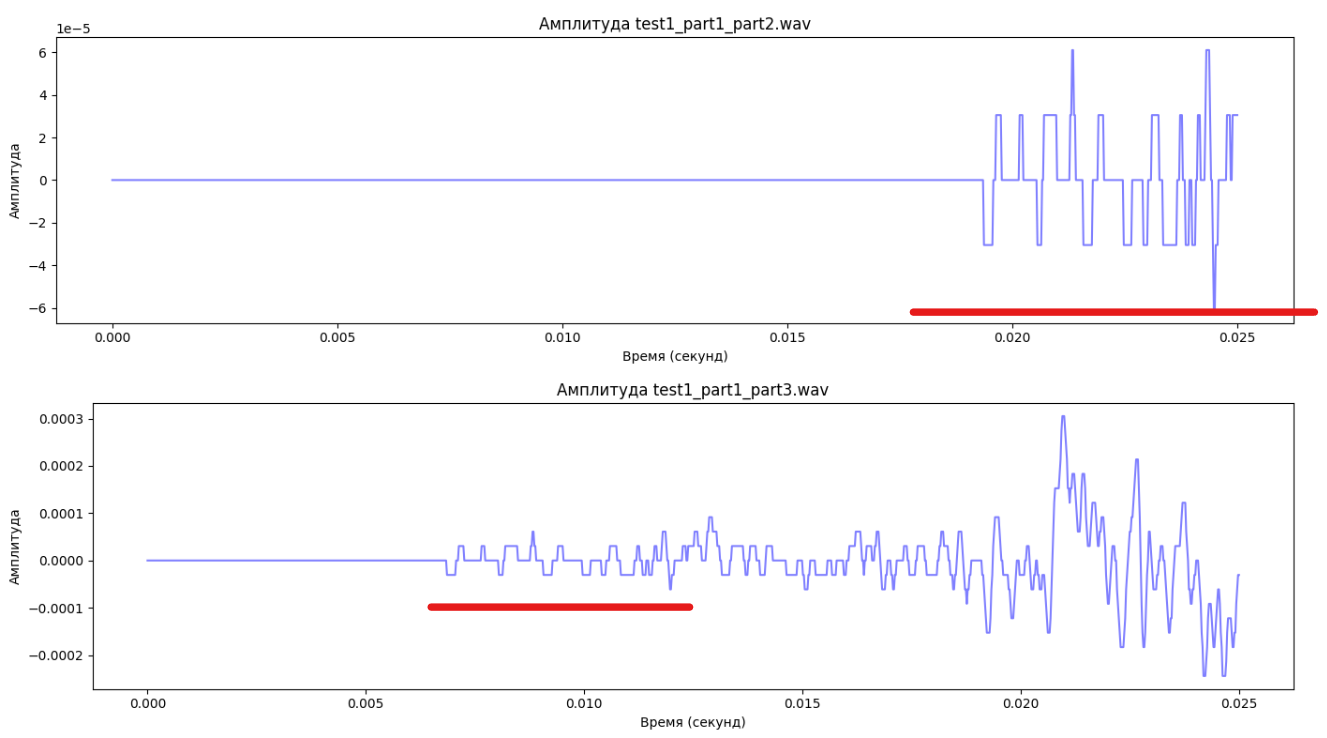
Рисунок 2. Визуализация соседних сегментов
Опытным путём был подобран оптимальный размер фрагментов аудиофайла, который составил 25 миллисекунд. Эта размерность была выбрана, потому что она обеспечивает подходящий для анализа результат и высокое быстродействие. Размер фрагментов в 25 миллисекунд позволяет эффективно выделять важные характеристики речевого сигнала, сохраняя при этом достаточную производительность обработки.
Фрагменты преобразуются в сеть при помощи функции tsnet_vg. Данная функция преобразует загруженные фрагменты в вершине и ребра графа. Полученный граф представлен ниже (см. рисунок 3)

Рисунок 3. Характерный граф аудиозаписи
Для каждого рассматриваемого диктора, было получено определенное количество графов. При помощи библиотеки networkx из каждого графа были извлечены сетевые характеристики. Для анализа полученных значений, было принято решение сравнить показатели двух дикторов.
При сравнении сетевых характеристик двух дикторов были отобраны наиболее чувствительные показатели, позволяющие точно определить принадлежность звукозаписи к конкретному диктору.
Рисунок 4. Сетевые характеристики двух дикторов
Таким образом, для данных дикторов наиболее чувствительными показателями, оказались: Average Degree (средняя степень) и Average Clustering Coefficient (средний коэффициент кластеризации).
Использование этих метрик позволяет классифицировать аудиозаписи и определить их владельцев. Дальнейшие исследования могут быть направлены на оптимизацию и расширение набора метрик, а также на улучшение алгоритмов обработки и анализа данных для повышения точности и эффективности распознавания дикторов.
Заключение. В настоящей работе исследован современный метод анализа временных рядов, основанный на преобразовании данных ряда в комплексную сеть.
В то время как оценки метрик сетевых структур существует достаточный набор решений, программные пакеты, обеспечивающие автоматизированную трансформации временных данных в сети, остаются узким местом.
Для эффективной реализации метода использован профессиональный R-пакет ts2net дополненный Python- инструментом с удобным пользовательским интерфейсом, который позволяет загружать сигнал, фильтровать его, обрезать и формировать временной ряд.
Предусмотрены средства количественной оценки сетевых структур и их визуализации.
Представлен двухэтапный процесс конвертирования временных рядов аудиозаписи в сетевые структуры.
- From Time Series to Networks in R with the ts2net Package : сайт. – URL: https://arxiv.org/pdf/2208.09660v1 (дата обращения 04.02.2024). – Текст: электронный
- An R package to transform time series into networks: сайт – URL: https://github.com/lnferreira/ts2net/ (дата обращения 04.02.2024). – Текст: электронный.
- Афанасьев, В. Н. А94 Анализ временных рядов и прогнозирование: учебник / В. Н. Афанасьев; Ай Пи Ар Медиа - Саратов, Оренбургский гос. ун-т. - Оренбург: 2020. - 286 с. ISBN 978-5-4497-0269-2 (Ай Пи Эр Медиа Саратов) ISBN (Оренбургский гос. ун-т.) – Текст: непосредственный
- Чеснов, М. С. Практическое применение теории графов / М. С. Чеснов, А. А. Репкина // Интеллектуальный потенциал XXI века инновационной России: Материалы XII Всероссийской научно-практической конференции студентов, Мценск, 26 мая 2023 года. – Орёл: Орловский государственный университет имени И. С. Тургенева, 2024. – С. 95–98. – EDN DXHKAR – Текст: непосредственный.
- Lacasa L., Luque B., Ballesteros F., Luque J., Nuño J. C. From time series to complex networks: The visibility graph // Proceedings of the National Academy of Sciences. 2008. Vol. 105, No. 13. P. 4972-4975. сайт. – URL: https://www.pnas.org/doi/10.1073/pnas.0709247105 (дата обращения 25.06.2024).
- Chen Y., Wang H. Horizontal visibility graph analysis of speech signals for speaker recognition // Journal of the Acoustical Society of America. 2020. Vol. 148, No. 3. P. 1205-1215.
- Delgado H., Quiroga R. Q. Information transfer in speech cortex: A graph-theoretical approach // PLoS ONE. 2013. Vol. 8, No. 3. e60070. сайт. – URL: https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0060070(дата обращения 25.06.2024).
Научные высказывания #99