МОДЕЛИ ТРАФИКА ДЛЯ ВИДЕОТРАФИКА
Моделирование видеотрафика стало ключевой проблемой в связи с растущей важностью цифровых видеосервисов в мультимедийных сетях. Помимо предоставления информации о структуре видеопоследовательностей, модели видеотрафика играют важную роль в характеристике и анализе сетевого трафика. Таким образом, точные модели видеотрафика необходимы для решения все еще открытых проблем, существующих в управлении мультимедийным трафиком, таких как распределение сетевых ресурсов, проектирование эффективных сетей для потоковых сервисов и предоставление гарантий качества обслуживания конечным пользователям.

Вступление. Сжатие видео или кодирование видео — это процесс уменьшения объема данных, необходимых для представления цифрового видеосигнала перед передачей. Как только данные сжаты, поток битов упаковывается и отправляется через Интернет. Дополняющая операция распаковки или декодирования восстанавливает цифровой видеосигнал из сжатого представления перед отображением. Управление скоростью является неотъемлемой частью большинства видеокодеров. Оно определяет количество бит или уровень качества закодированного кадра. Существует два типа регуляторов скорости для кодирования и сжатия видеосигналов: постоянная скорость передачи данных (CBR) и VBR.
CBR фокусируется на повышении точности согласования между целевой скоростью передачи данных и фактической скоростью передачи данных и удовлетворении ограничениям низкой задержки и буфера. В результате наблюдаются колебания качества видео из-за изменений сцены и другого видеоконтента. В случаях, когда ограничение скорости или задержки не такое строгое, как в видео в реальном времени, для поддержания постоянного качества можно использовать VBR. VBR обеспечивает лучшее качество видео и обеспечивает более эффективное использование ресурсов, чем CBR. Однако видеотрафик VBR обладает более высокой интенсивностью, а также корреляционными свойствами, которые необходимо должным образом учитывать для достижения хорошего качества обслуживания наряду с высоким использованием полосы пропускания. Исследования показали, что более высокое использование может быть достигается за счет надлежащего использования корреляционных характеристик посредством прогнозирования трафика [1].
Для кодирования видео были разработаны различные стандарты, включая H.261, H.263, MPEG-1, MPEG-2, MPEG-4 и H.264. H.264/MPEG-4 AVC представляет собой большой скачок в технологии сжатия видео, при этом средняя скорость передачи данных для данного качества видео обычно снижается на 50% по сравнению с MPEG-2 и примерно на 30% по сравнению с MPEG-4 part 2. H.264 в настоящее время является одним из наиболее используемых видеоформатов, поскольку они охватывают огромный спектр приложений, таких как видеоконференции, мобильные сервисы и хранилище видео высокой четкости. Еще более новый стандарт H.265 направлен на достижение того же качества видео, что и H.264, при более низких скоростях передачи. Тремя основными структурными особенностями, которые являются общими для кодеров H.264 и H.265, являются три типа кадров (I, PB), периодическая структура, в которой кодируются видеокадры, и шаблон, в котором генерируются эти кадры. Периодическая структура называется группой изображений (GoP). Каждое видео кадр является либо внутрикодированным (I-кадр), кодированным с прямым прогнозированием (P-кадр) с предсказанием с компенсацией движения из предыдущего I- или P-кадра, либо двунаправленным прогнозирующим кодированием (B-кадр) в соответствии с его положением в структуре GoP [2].
На рисунке 1 показана структура GoP кодированной последовательности IBBBPBBBPBBBPBBBI, состоящая из 16 кадров с 1 I-кадром, 3 P-кадрами и 12 B-кадрами (обозначается как G16B3).
Первый кадр кодируется как I-кадр. Следующие три B-кадра, B-1, B-2 и B-3, не могут быть закодированы сразу, поскольку они ожидают следующего P-кадра. Поэтому они помещаются в буфере. Когда кадр P-4 поступает в кодер, он однонаправленно кодируется с использованием первого кадра I-frame в качестве опорного. Теперь, когда P-кадр закодирован, могут быть закодированы B-1, B-2 и B-3 (которые являются двунаправленными и нуждаются в ссылках как в прошлом, так и в будущем). Таким образом, B-кадры создаются на основе опорных кадров, то есть кадров P и If.
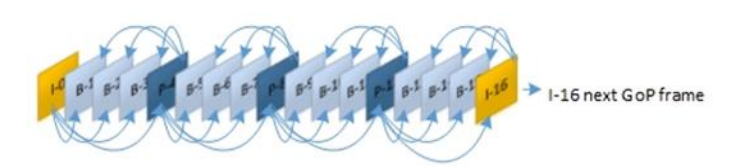
Рисунок 1. G16B3-Структура группы изображений (GoP) [3]
B-кадры занимают наибольшее количество кадров в кадрах GoP H.264. В дополнение, было замечено, что трассировка B-кадров более интенсивна, чем других кадров, что подразумевает, что распределение полосы пропускания для B-кадров будет более сложным, чем для других типов кадров. С другой стороны, B-кадры считаются менее важными по сравнению с I-кадрами и P-кадрами, и удаление B-кадра не окажет большого влияния на QoS, поскольку кадры, передаваемые после B-кадра, не зависят от этого кадра. Кроме того, B-кадры содержат только временную информацию, и их потеря может привести только к артефактам движения, которые может быть трудно заметить, если уровень потерь не высок.
Модели видеотрафика. Исследования по моделированию видеотрафика можно в общих чертах разделить на две категории:
а) модели скорости передачи данных
б) модели размера кадра.
В модели скорости передачи данных для целей прогнозирования производительности вычисляется только скорость, с которой данные поступают по каналу.
Почти все модели видеотрафика, включая модели первого порядка (AR), DAR, Марковский процесс обновления (MRP), BAR и модель ARIMA или модель авторегрессионного интегрированного скользящего среднего, подпадают под эту категорию.
Эти модели, как правило, обеспечивают хорошие результаты приводит к прогнозированию средней вероятности потери пакетов и вероятности переполнения буфера.
Однако у них есть недостаток, заключающийся в невозможности определить процент кадров, подверженных потере, для разных кадров, поскольку даже небольшая скорость потери данных, связанная с I-кадрами, может значительно повлиять на качество восприятия принимаемого видео, в то время как тот же объем потери данных в B-кадрах оказал бы гораздо меньшее влияние. Напротив, при использовании модели размера кадра генерируются размеры отдельных видеокадров, и, следовательно, информация о скорости передачи данных может быть получена из информация о размере кадра [4].
Модели скорости передачи данных. Моделирование видеотрафика VBR было широко изучено, и в литературе были предложены различные модели для учета характеристик видеопоследовательностей и точного прогнозирования производительности сети. В этом разделе представлен обзор предыдущих исследований моделей видеотрафика со скоростью передачи данных. Эти модели можно разделить на три категории: вероятностные модели, AR-модели и модели с марковской модуляцией.
Первая категория состоит из моделей, основанных на распределениях вероятности. Лазарис и др. провели исследование распределения размера кадра трафика видеоконференций MPEG-4.
Наилучшее соответствие наблюдалось при распределении V типа Пирсона (также известном как инвертированное гамма-распределение) по сравнению с гамма-, вейбулловским, логнормальным и экспоненциальным распределениями; однако степень хорошего соответствия для V типа Пирсона значительно варьировалась и не была высокоточной. Поскольку ни одна из попыток подгонки, включая Pearson V, не смогла достичь идеальной точности из-за характеристик функции автоматической корреляции (ACF) трафика видеоконференции, была построена модель путем независимого генерирования размера кадра для I, P и B-кадров. Достоверность результата была проверена с помощью статистического теста KS для всех 12 попыток подгонки. Тест KS используется для определения того, существенно ли различаются два набора данных и являются ли наборы данных непараметрическими. Результаты показали, что размер кадров, создаваемых видеокодером MPEG, был сильно коррелирован и подтверждал утверждения о том, что LRD важен, в отличие от других исследований видеотрафика VBR, где распространенность LRD была спорной. Хотя для распределения по размеру кадра было предложено несколько моделей, включая логнормальную, гамму и гамма/логнормальную, захват структуры ACF трасс VBR является более сложной задачей по сравнению с подгонкой модели к распределению по размеру кадра из-за того факта, что трассы VBR демонстрируют обе Свойства LRD и SRD [5].
Вторая категория состоит из моделей дополненной реальности, которые обычно применяются с целью захвата свойств ACF закодированных видеодорожек. Однако из-за динамического и учитывая сложные свойства видеотрафика, поиск подходящей AR-модели, представляющей различные статистические характеристики, может оказаться довольно сложной задачей. Первая модель AR была использована для моделирования видеотрафика в 1988 году, и модели AR широко использовались, как и модели скользящего среднего (MA) и авторегрессивные модели скользящего среднего (ARMA). Все эти видеомодели являются моделями скорости передачи данных, которые генерируют скорость, с которой данные поступают по каналу связи, для прогнозирования производительности. Эти модели считаются хорошими для предсказывают среднюю вероятность потери пакетов и вероятность переполнения буфера, но терпят неудачу, когда дело доходит до определения влияния потери данных, включающей B, I или P-кадры, на качество видео.
Совсем недавно Дейли и др. проанализировали B, I и P-кадры видеотрасс H.265 отдельно для прогнозирования оптимизации передачи видео в пассивных оптических сетях ethernet, используя нелинейную авторегрессивную нейронную сеть, основанную на размере очереди. Эта модель достигла точности прогнозирования выше 90% для всех категорий данных. Однако модели дополненной реальности страдают из-за сложности аппроксимации функции ACF эмпирических наборов данных [6].
Третья категория состоит из моделей с марковской модуляцией. Кастринакис и др. разработал гибридную модель для прогнозирования видеотрафика, генерируемого компьютером пользователя в течение дня, используя комбинацию кластеризации с цепью Маркова и модель коэффициента подобия индекса Жаккарда. Модель достигла относительной процентной погрешности от 2,5% до 6,3% для I кадров и от 2,1% до 6,2% для прогнозирования размера P-кадра для 1-го набора данных и такой низкой, как относительная процентная частота ошибок от 2,5% до 4,2% для размера кадра P для 2-го набора данных с использованием модели марковской кластеризации Jaccard , основанной на индексах. В другом исследовании Калампогия и Кутсакис использовали модель линейной регрессии для прогнозирования размера B-кадра для видео в кодировках H.264 и H.265, которая обеспечивала высокую точность для видео в формате MPEG-4, но не давала точных результатов прогнозирования для трасс H.264 и H.265. Поэтому для прогнозирования размера B-кадра видео в кодировках H.264 и H.265 была использована другая марковская модель путем разделения B-кадров на два подмножества на основе размера кадра для уменьшения полосы пропускания и сглаживания видеопотока. Была достигнута минимальная относительная процентная погрешность между фактическим и прогнозируемым трафиком, варьирующаяся от 1,4% для трасс H.264 до 2,6% для трасс H.265 [7]. Хотя марковские модели могут эффективно фиксировать LRD видеотрасс, обычно трудно точно определить и сегментировать видеоисточники по различным состояниям во временной области из-за динамической природы видеотрафика. Основным недостатком этих моделей является экспоненциальное затухание автокорреляционные функции сгенерированных последовательностей, которые приводят к неточным оценкам производительности.
- Рафальская, М. И. Модель обработки видеотрафика в устройствах коммутации мультисервисной сети связи / М. И. Рафальская // Современное состояние и перспективы развития инфокоммуникационных сетей связи специального назначения: Сборник материалов научно-практической конференции, Санкт-Петербург, 23 марта 2023 года. –С. 71-80
- Umer, M. A. Collective servicing of heterogenous traffic streams over 3GPP LTE network and application of access control / M. A. Umer, M. S. Stepanov // T-Comm. – 2022. – Vol. 16, No. 3. – P. 43-49.
- Bryan Samis / Back to basics: GOPs explained. AWS Elemental MediaConvert, Media & Entertainment, Media Services, Thought Leadership https://aws.amazon.com/blogs/media/part-1-back-to-basics-gops-explained/, 2021
- Назад к основам: что такое «группа изображений» (GOP)? by AWS Central EurAsia & Russia Team, 2021. AWS Elemental MediaConvert, Media & Entertainment. https://aws.amazon.com/ru/blogs/rus/media-part-1-back-to-basics-gops-explained/
- Maratsolas, P. Koutsakis, and A. Lazaris, "Video Activity-based Traffic Policing: A New Paradigm," IEEE Transactions on Multimedia, vol. 16, no. 5, pp. 1446-1459, 2014
- C. Daly, D. L. Moore, and R. J. Haddad, "Nonlinear Auto-regressive Neural Network Model for Forecasting Hi-Def H. 265 Video Traffic over Ethernet Passive Optical Networks," Charlotte NC, USA, 2017, pp. 1-7
- Kalampogia and P. Koutsakis, "H. 264 and H. 265 video bandwidth prediction," IEEE Transactions on Multimedia, vol. 20, no. 1, pp. 171-182, 2017.
Научные высказывания #99