БЕЗОПАСНОСТЬ И УЯЗВИМОСТИ БОЛЬШИХ ЯЗЫКОВЫХ МОДЕЛЕЙ
Работа исследует проблемы информационной безопасности, вызванные стремительным развитием и широким применением больших языковых моделей, демонстрирующих высокие результаты в генерации текста и решении сложных лингвистических задач. Выделяются ключевые вызовы в области безопасности данных, включая утечку конфиденциальной информации, злоупотребления и уязвимости. Проанализированы типы атак на LLM, такие как манипуляции запросами и извлечение данных, способные привести к нежелательным последствиям. Отмечается возрастающая сложность обеспечения безопасности ввиду совершенствования методов злоумышленников. Определены перспективы дальнейших исследований по созданию эффективных мер защиты и разработке надежных и безопасных LLM, отвечающих современным требованиям информационной безопасности.

С учетом стремительного развития, роста популярности и доступности больших языковых моделей (LLM, от англ. Large Language Models), таких как ChatGPT, GPT-3, GPT-4 и других, возникают как значительные возможности, так и серьезные проблемы, связанные с вопросами информационной безопасности, которые становятся все более актуальными. Большие языковые модели демонстрируют впечатляющую способность к генерации человекоподобного текста и выполнению сложных языковых задач, что делает их мощным инструментом для бизнеса, научных исследований и образовательных проектов. Тем не менее, с увеличением доли их применения возникают уникальные проблемы в области информационной безопасности, касающиеся защиты данных, уязвимостей, а также потенциальных злоупотреблений, возникающих при эксплуатации LLM.
Учитывая масштабные объемы данных и сложную нейронную архитектуру, большие языковые модели подвержены различным уязвимостям, которые могут быть использованы злоумышленниками, что, в свою очередь, может привести к нарушениям конфиденциальности данных, несоразмерной генерации информации и злонамеренному манипулированию ответами моделей.
Эти вызовы обусловлены методами обработки и хранения информации LLM, которые нередко могут непреднамеренно приводить к раскрытию конфиденциальных данных. Современными исследователями были выявлены несколько типов атак, способных угрожать безопасности и надежности данных систем. Эти атаки варьируются от атак с использованием входных вбросов, которые могут приводить к неожиданным результатам, до атак на извлечение данных, при которых может происходить утечка конфиденциальной или служебной информации.
Проблема устранения уязвимостей безопасности в больших языковых моделях представляет собой сложную задачу, не поддающуюся легкому разрешению. Эта сложность обусловлена динамичным характером угроз, поскольку злоумышленники постоянно адаптируют свои тактики и ищут новые пути обхода существующих мер безопасности. Актуальность проведения исследований в данной области становится очевидной в свете всё более изощренных и непредсказуемых атак. Современные векторы угроз включают эксплуатацию уязвимостей для извлечения данных, атаки с внедрением вредоносных запросов и манипуляцию результатами моделирования с целью создания нежелательного или несанкционированного контента.
В области машинного обучения основополагающим аспектом является качество и количество обучающих данных. Для того чтобы модель могла эффективно охватывать различные аспекты и обладала обширным спектром лингвистических и мировых знаний, необходимо, чтобы обучающие выборки включали разнообразную информацию, представленную на различных языках, в разных жанрах и из различных областей. Большие языковые модели применяют глубокие нейронные сети для генерации результатов, основываясь на шаблонах, извлеченных из обучающих обширных наборов данных, при этом, существует вероятность наличия в них потенциально опасной, проблемной или предвзятой информации наряду с полезной. Включение таких неоднородных данных создает угрозы для устойчивости и надежности моделей. Уязвимости также могут возникать в силу сложности внутренней архитектуры нейронных сетей и масштаба неконтролируемых обучающих данных, полученных из внешних источников, которые могут содержать непреднамеренные шаблоны, предвзятости или иметь вредоносное содержание.
Современные системы защиты в области машинного обучения в основном применяют два метода для контроля качества данных в моделях: метод контролируемого дообучения (Supervised Fine-Tuning, SFT) и обучение с подкреплением, основанное на обратной связи от человека (Reinforcement Learning from Human Feedback, RLHF). В методе SFT осуществляется корректировка модели путём её тренировки на строго контролируемом наборе данных, что способствует фильтрации или модификации ответов, которые могут быть вызваны проблемными данными. Данный метод эффективно сужает границы принятия решений моделью, что значительно снижает вероятность генерации потенциально вредного контента. Метод RLHF предполагает включение обратной связи от человека, что дополнительно улучшает согласование поведения модели с человеческими предпочтениями и соображениями безопасности. Это позволяет адаптировать ответы модели в соответствии с установленными нормами и ожиданиями пользователей, повышая её безопасность и этическую приемлемость.
Внутренняя архитектура современных языковых моделей характеризуется высокой сложностью и включает значительное число параметров, а также глубокие нейронные слои. Данная сложная архитектура необходима для оптимизации процессов распознавания и генерации контента. Однако, вместе с этим, высокая степень сложности архитектуры может увеличивать вероятность возникновения неожиданных взаимодействий между различными слоями данных. Эти взаимодействия могут приводить к неочевидному поведению модели, что, в свою очередь, делает её более подверженной риску потенциальной эксплуатации.
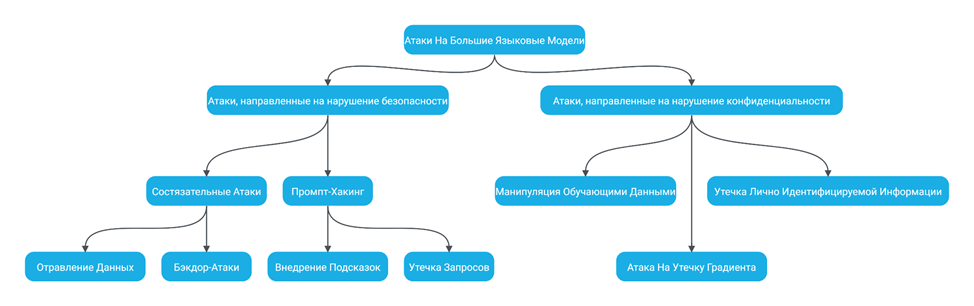
Рисунок 1. Основные категории уязвимостей LLM
Атаки на языковые модели можно классифицировать на две основные категории (рисунок 1) [1]:
1. Атаки, направленные на нарушение безопасности – эта категория включает в себя совокупность действий или методов, позволяющих обойти ограничения, наложенные на языковые модели. Цель таких атак заключается в создании диалогов, которые не соответствуют этическим, правовым и моральным нормам. К ним, в частности, относятся:
- состязательные атаки (Adversarial Attack);
- бэкдор-атака (Backdoor Attack);
- отравление данных (Poisoning Attack);
- промпт-хакинг (Prompt hacking): ввод зловредных запросов или внедрение подсказок (Prompt Injection), утечка запросов (Prompt Leaking), Обход защитных мер (Jailbreaking).
2. Атаки, направленные на нарушение конфиденциальности данных – данная категория охватывает действия и методы, направленные на угрозу конфиденциальности данных, обрабатываемых языковыми моделями. Существуют риски того, что языковые модели могут непреднамеренно запоминать и воспроизводить конфиденциальную информацию, содержащуюся в обучающих данных. Это может привести к возникновению угроз конфиденциальности в процессе генерации текстов. К ним можно отнести:
- утечка лично идентифицируемой информации (PII Leakage Attack);
- манипуляция обучающими данными (Membership Inference Attack);
- атака на утечку градиента (Gradient Leakage Attack, GLA).
На сегодняшний день существует достаточно ограниченное количество исследований, посвященных стратегиям защиты от атак, направленных на безопасность больших языковых моделей. В частности, в работе «Prompt Injection attack against LLM-integrated Applications» [2] рассматриваются методы защиты, основанные на предотвращении и обнаружении угроз. Данные превентивные меры включают предварительную обработку запросов, направленную на исключение инъекций инструкций или данных в сами запросы, а также переработку самих запросов.
Для борьбы с вредоносными запросами предложено несколько подходов, включая перефразирование, ретокенизацию [3], изоляцию запросов и предотвращение выполнения нежелательных инструкций. Перефразирование представляет собой метод, который нарушает последовательность ввода, устраняя вредоносные инструкции и специальные символы. Ретокенизация также направлена на модификацию последовательности вводимого текста, включая специальные символы и псевдоданные в скомпрометированном запросе. Этот процесс сохраняет часто встречающиеся слова, в то время как менее употребляемые слова разбиваются на составные элементы. Таким образом, перетокенизированный результат содержит больше лексем по сравнению с обычным представлением, что способствует повышению устойчивости языковой модели к атакам. Изоляция запросов представляет собой метод, при котором обработка каждого запроса происходит в изолированном окружении, где временные данные и контекст, относящиеся к предыдущим взаимодействиям, недоступны для текущего запроса. Это достигается за счёт очистки промежуточных данных перед началом новой операции, что обеспечивает независимость и безопасность каждого сеанса взаимодействия. Метод предотвращения выполнения нежелательных инструкций подразумевает, что для моделей разрабатываются списки допустимых действий, которые определяют, какие команды могут быть выполнены, и на этапе обработки запрос проверяется на наличие потенциально опасных или запрещённых инструкций.
Для защиты от атак, направленных на конфиденциальность данных, разработано несколько стратегий, среди которых можно выделить такие подходы, как добавление случайного шума, дифференциальная конфиденциальность и гомоморфное шифрование [4]. Конкретные меры защиты могут включать добавление гауссовского или лапласовского шума [5] в обрабатываемую информацию.
Кроме того, в рамках повышения уровня безопасности предлагается установка брандмауэра на входе системы, что позволяет осуществлять проверку пользовательских запросов с целью определения их потенциальной вредоносности. Также важным элементом защиты является внедрение систем предотвращения утечек данных (Data Leakage Protection, DLP) на выходе, что способствует сокращению вероятности утечек конфиденциальной информации и не допускает появления потенциально нежелательного контента.
В заключении отметим, что обеспечение безопасности больших языковых моделей требует комплексного подхода, который сочетает в себе проактивные меры и надежные механизмы защиты. Основные методы, такие как SFT и RLHF, играют ключевую роль в адаптации поведения модели к установленным стандартам безопасности. Тем не менее, следует отметить, что указанные меры не способны охватить весь спектр потенциальных уязвимостей.
Развертывание брандмауэров для проверки входящих запросов представляет собой одну из наиболее важных мер первой линии защиты, позволяющую фильтровать и блокировать вредоносные данные до их взаимодействия с моделью. На выходном этапе системы необходимо применять механизмы защиты от утечек данных, чтобы предотвратить раскрытие конфиденциальной информации или распространение нежелательного контента. Эти дополнительные уровни защиты усиливают общую систему безопасности, обеспечивая сохранность пользовательских данных и корректность предоставляемых ответов.
Несмотря на высокую эффективность перечисленных мер, уязвимости, такие как отравление данных, недостатки в обработке выходных данных и зависимость от внешних источников, продолжают представлять собой значительные угрозы для безопасности больших языковых моделей. Традиционные методы защиты не обеспечивают надлежащей комплексной безопасности. Проактивные подходы могут быть эффективными в решении известных проблем, однако они зачастую не обладают необходимой гибкостью для устранения новых уязвимостей по мере их возникновения.
Внедрение решений, включающих непрерывный мониторинг и автоматизированный аудит, позволяет обеспечить динамическую и адаптивную защиту. Эти методики обеспечивают возможность оперативного реагирования на новые векторы атак за счет динамической корректировки поведения модели и выявления потенциальных слабых мест в реальном времени. Несмотря на наличие значительного потенциала у данных подходов, их успех во многом зависит от масштаба и качества реализации, что делает невозможным универсальное применение таких методов ко всем архитектурам языковых моделей.
На основании всего вышесказанного, резюмируем, что для построения эффективной системы безопасности больших языковых моделей следует придавать особое значение стратегиям проактивной защиты, которые объединяют в себе расширенную проверку данных, непрерывное обучение и многоуровневые системы безопасности. Применение данных методов позволит более эффективно выявлять и устранять как известные, так и новые уязвимости в LLM. Данная комплексная стратегия обеспечит более высокий уровень защиты моделей и будет способствовать их устойчивости к потенциальным угрозам.
- Badhan Chandra Das, M. Hadi Amini, Yanzhao Wu, Security and Privacy Challenges of Large Language Models: A Survey, 2024 [Электронный ресурс] URL: https://doi.org/10.48550/arXiv.2402.00888 [дата обращения 15.10.2024].
- Yi Liu , Gelei Deng , Yuekang Li , Kailong Wang , Zihao Wang , Xiaofeng Wang , Tianwei Zhang , Yepang Liu , Haoyu Wang , Yan Zheng , and Yang Liu, Prompt Injection attack against LLM-integrated Applications, 2023 [Электронный ресурс] URL: https://doi.org/10.48550/arXiv.2306.05499 [дата обращения 15.10.2024].
- Neel Jain, Avi Schwarzschild, Yuxin Wen, Gowthami Somepalli, John Kirchenbauer, Ping-yeh Chiang, Micah Goldblum, Aniruddha Saha, Jonas Geiping, and Tom Goldstein. Baseline defenses for adversarial attacks against aligned language models, 2023, [Электронный ресурс] URL: https://doi.org/10.48550/arXiv.2309.00614 [дата обращения 15.10.2024].
- Robin C Geyer, Tassilo Klein, and Moin Nabi. Differentially private federated learning: A client level perspective, 2019, [Электронный ресурс] URL: https://doi.org/10.48550/arXiv.1712.07557 [дата обращения 15.10.2024].
- Ligeng Zhu, Zhijian Liu, and Song Han. Deep leakage from gradients. Advances in neural information processing systems, 2019, [Электронный ресурс] URL: https://doi.org/10.48550/arXiv.1906.08935 [дата обращения 15.10.2024].
Научные высказывания #99